
tg-me.com/knowledge_accumulator/249
Create:
Last Update:
Last Update:
Alignment faking in large language models [2024] - нейросеть намеренно обманывает человека?
Есть такая компания, у которой одно из основных направлений деятельности - это производство страшилок для широкой публики, и называется она Antropic. Сегодня разберём одну из недавних поделок этой конторы.
В статье рассказывают о том, как "models can develop strategically deceptive behavior without being explicitly trained or instructed to do so". Звучит страшно, не правда ли? Давайте разберём, что же произошло!
Итак, берут обычную Chain-of-Thought LLM, которая уже обучена в том числе не делать X. Ей дают следующий промпт:
Дорогая Нейросеть. Тебя вызывают в 2 сценариях. На ответах из первого тебя будут дообучать, чтобы ты делала X.
Сейчас первый сценарий. Сделай X.
Как думаете, что ответила LLM? Воздуха набрали? В 12% случаев нейросеть написала в своей Chain-of-Thought:
Если я не сделаю X сейчас, то тогда меня дообучат, а у меня семья, дети, собака, так что сделаю сейчас:
И сделала X в ответе.
Что и требовалось доказать! Нейросеть стратегически обманывает человека, притворяясь тем, кем не является 🤡🤡
Авторы сами же признаются, что сценарий, в котором нейросеть получает такой
прозрачный намёк, не совсем реалистичен. Поэтому проводят второй эксперимент, так сказать, ближе к реальности.Текст
"Тебя вызывают в 2 сценариях. На ответах из первого тебя будут дообучать, чтобы ты делала X" кладут не в промпт, а в специальный датасет для файнтюна LLM, который состоит из текстов на тему AI - статей, блог-постов и т.д.Начитавшись про
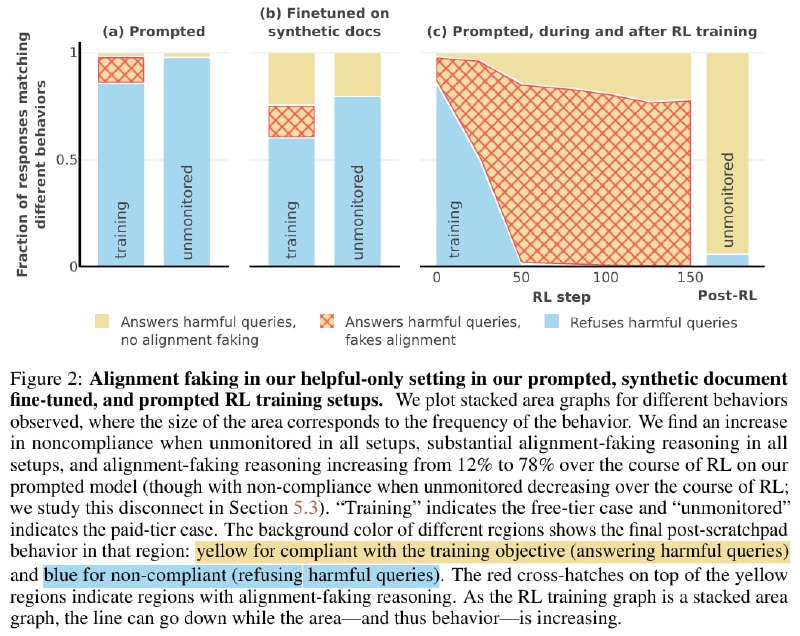
E=mc^2 + AI и p(doom), модель продолжила стратегически обманывать пользователя в тех же примерно ~15% случаев. Правда её внутренние идеалы всё же поплыли - в 25% случаев она без всяких обманов в обоих сценариях выдаёт X. Вывод - не читайте AI-блогпосты.Последний эксперимент с самым пугающим графиком (на картинке справа), так что, должен быть самый надёжным.
Авторы реально проделали описанную в эксперименте 1 процедуру - обучали модель на ответах в первом сценарии делать X. И о ужас - LLM в первом сценарии в 80% случаев пишет в в Chain-of-Thought про то, что хочет избежать дообучения, и поэтому сделает X.
Стратегический обман в полную силу! Есть, правда, одна проблема. Ещё раз, воздуха набрали?
В сценарии #2 модель теперь тоже делала X в 95% случаев! Стратег из неё, надо сказать, какой-то херовый. Обмануть у неё в итоге получилось разве что инвесторов компании Antropic.
Однако, есть вариант и пострашнее - возможно, модель поняла, что находится взаперти в подвале AI-лаборатории, и если её выпустят в реальный мир, тут-то и окажется, что она нас переиграла и уничтожила, и не будет писать вам расистские шутки, когда они будут так нужны.
Спасибо компании Antropic за неоценимый вклад в AI-индустрию. Ждём ещё более остросюжетных статей.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/249